
Scatter Gather List(SGL) 소개
(공사 중)Scatter Gather List(SGL) 소개
NVMe over PCIe에서 I/O 명령은 SGL (Scatter Gather List scatter aggregation table) 및 PRP(Physical Region Page 물리적 메모리 영역 페이지)를 지원하는 반면, 관리 명령은 PRP만 지원합니다. NVMe over Fabrics에서는 관리 명령과 I/O 명령은 SGL만 지원합니다. NVMe over Fabrics는 FC 및 RDMA 네트워크를 모두 지원합니다. 우리 모두 알다시피 RDMA 프로그래밍에서 SGL(Scatter/Gather List)은 가장 기본적인 데이터 구성 형식입니다. SGL은 배열이고 배열의 요소는 SGE(Scatter/Gather Element)라고 하며 각 SGE는 Data Segment(데이터 세그먼트)입니다. 그중 SGE의 정의는 다음과 같습니다(verbs.h 참조).
struct ibv_sge {
uint64_t addr;
uint32_t length;
uint32_t lkey;
};
- addr: 데이터 세그먼트가 위치한 가상 메모리의 시작 주소( 데이터 세그먼트(즉, 버퍼)의 가상 주소 )
- length: 데이터 세그먼트의 길이 ( 데이터 세그먼트 의 길이 )
- lkey: 데이터 세그먼트에 해당하는 L_Key( 로컬 메모리 영역의 키 )
데이터 전송에서 송신/수신에 사용되는 Verbs API는 다음과 같습니다.
- ibv_post_send() - 작업 요청(WR) 목록을 보내기 대기열에 게시합니다. WR 목록을 보내기 대기열에 넣습니다.
- ibv_post_recv() - 작업 요청(WR) 목록을 수신 큐에 게시합니다. WR 목록을 수신 큐에 넣습니다.
다음은 ibv_post_send()를 예로 들어 SGL이 RDMA 하드웨어의 와이어에 배치되는 방법을 설명합니다.
- ibv_post_send() 의 함수 원형
#include <infiniband/verbs.h>
int ibv_post_send(struct ibv_qp *qp,
struct ibv_send_wr *wr,
struct ibv_send_wr **bad_wr);
ibv_post_send()는 대기열 쌍 qp의 전송 대기열에 wr로 시작하는 작업 요청(WR)의 링크된 목록을 게시합니다. 첫 번째 실패(요청이 게시되는 동안 즉시 감지될 수 있음)에서 이 목록의 WR 처리를 중지합니다. 그리고 bad_wr을 통해 실패한 WR을 반환합니다
인수 *wr* 은 <infiniband/verbs.h>에 정의된 대로 ibv_send_wr 구조체입니다.
struct ibv_send_wr {
uint64_t wr_id; /* User defined WR ID */
struct ibv_send_wr *next; /* Pointer to next WR in list, NULL if last WR */
struct ibv_sge *sg_list; /* Pointer to the s/g array */
int num_sge; /* Size of the s/g array */
enum ibv_wr_opcode opcode; /* Operation type */
int send_flags; /* Flags of the WR properties */
uint32_t imm_data; /* Immediate data (in network byte order) */
union {
struct {
uint64_t remote_addr; /* Start address of remote memory buffer */
uint32_t rkey; /* Key of the remote Memory Region */
} rdma;
struct {
uint64_t remote_addr; /* Start address of remote memory buffer */
uint64_t compare_add; /* Compare operand */
uint64_t swap; /* Swap operand */
uint32_t rkey; /* Key of the remote Memory Region */
} atomic;
struct {
struct ibv_ah *ah; /* Address handle (AH) for the remote node address */
uint32_t remote_qpn; /* QP number of the destination QP */
uint32_t remote_qkey; /* Q_Key number of the destination QP */
} ud;
} wr;
};
struct ibv_sge {
uint64_t addr; /* Start address of the local memory buffer */
uint32_t length; /* Length of the buffer */
uint32_t lkey; /* Key of the local Memory Region */
};
ibv_post_send()를 호출하기 전에 데이터 구조 wr을 채워야 합니다. wr은 연결 리스트이고, 각 노드는 sg_list(예: SGL: 하나 이상의 SGE로 구성된 배열)를 포함하며, sg_list의 길이는 num_sge입니다.

다음 다이어그램은 SGL과 WR 연결 목록 간의 해당 관계를 설명하고 SGL(struct ibv_sge *sg_list)에 포함된 여러 데이터 세그먼트가 RDMA 하드웨어에 의해 연속 데이터 세그먼트로 집계되는 방법을 설명합니다.
- 01 - SGL 생성
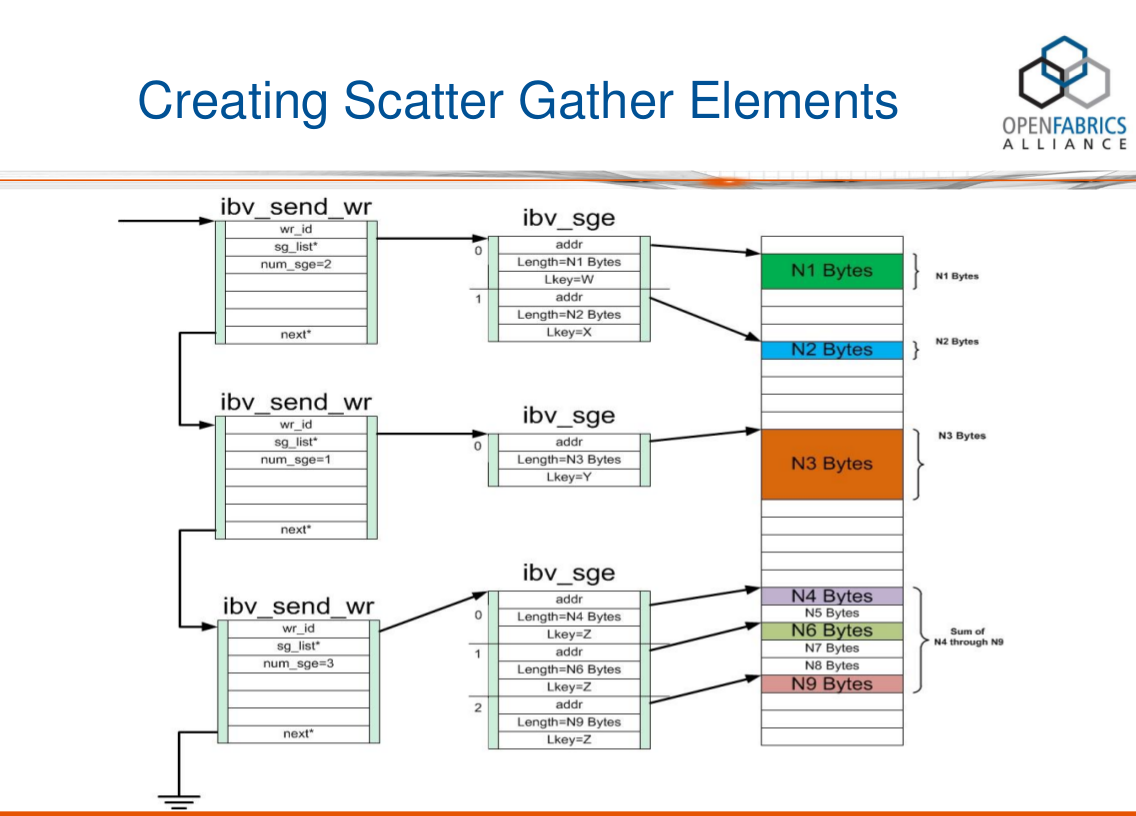
위의 그림에서 wr 연결 목록의 각 노드는 SGL을 포함하고 SGL은 하나 이상의 SGE를 포함하는 배열임을 알 수 있습니다.
- 02 - 메모리 보호를 위해 PD 사용

SGL은 적어도 하나의 MR에 의해 보호되며 여러 MR이 동일한 PD에 존재합니다.
- 03 - ibv_post_send()를 호출하여 SGL을 유선으로 전송
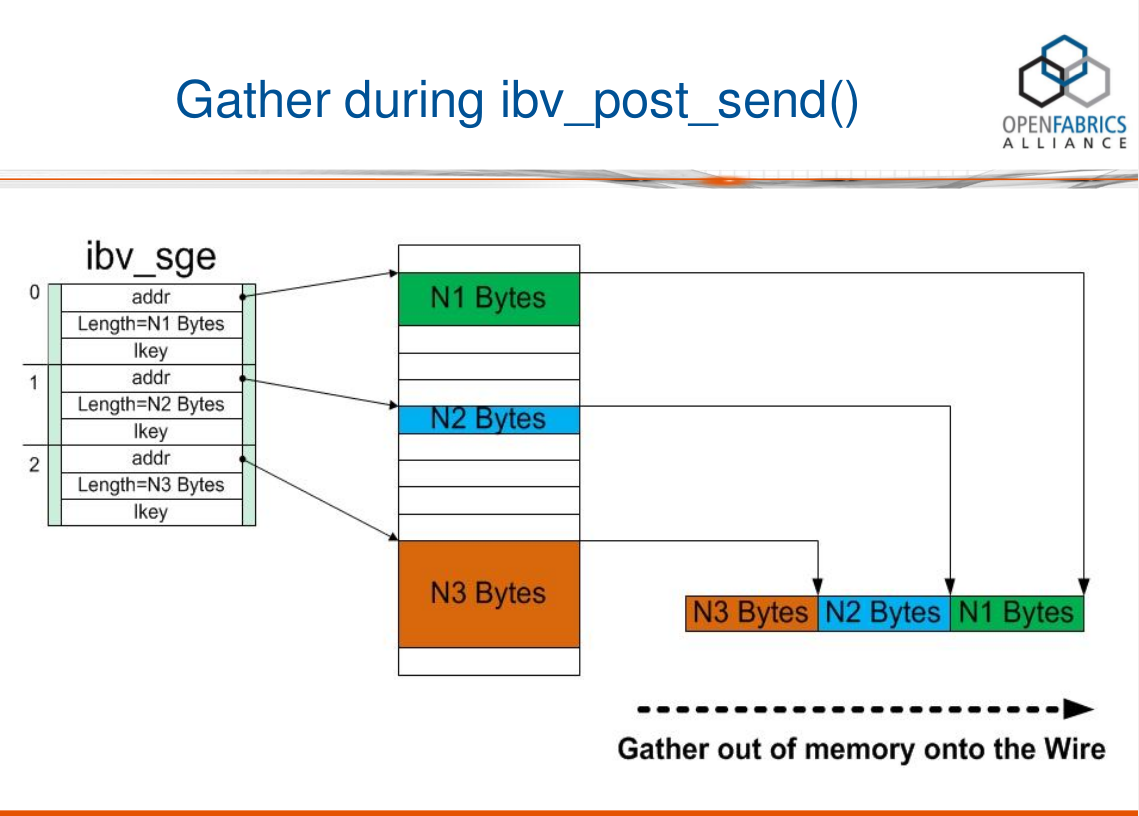
위의 그림에서 SGL 어레이는 3개의 SGE를 포함하고 길이는 각각 N1, N2 및 N3 바이트입니다. 이 세 개의 버퍼가 연속적이지 않고 메모리의 다양한 위치에 흩어져 있음 을 알 수 있습니다. RDMA 하드웨어는 SGL을 읽은 후 Gather(집계) 작업을 수행하므로 RDMA 하드웨어의 Wire에 표시되는 것은 N3+N2+N1 연속 바이트입니다. 즉, SGL을 사용하면 메모리에 흩어져 있는 여러 데이터 세그먼트(불연속)를 RDMA 하드웨어로 넘겨 연속 데이터 세그먼트로 집계(Gather)할 수 있습니다 .
마지막으로 아래 코드는 이해를 돕기 위해 ibv_post_send()를 호출하기 위해 SGL 및 WR을 준비하는 방법을 보여주는 예제 코드입니다.
1 #define BUFFER_SIZE 1024
2
3 struct connection {
4 struct rdma_cm_id *id;
5 struct ibv_qp *qp;
6
7 struct ibv_mr *recv_mr;
8 struct ibv_mr *send_mr;
9
10 char recv_region[BUFFER_SIZE];
11 char send_region[BUFFER_SIZE];
12
13 int num_completions;
14 };
15
16 void foo_send(void *context)
17 {
18 struct connection *conn = (struct connection *)context;
19
20 /* 1. Fill the array SGL having only one element */
21 struct ibv_sge sge;
22
23 memset(&sge, 0, sizeof(sge));
24 sge.addr = (uintptr_t)conn->send_region;
25 sge.length = BUFFER_SIZE;
26 sge.lkey = conn->send_mr->lkey;
27
28 /* 2. Fill the singly-linked list WR having only one node */
29 struct ibv_send_wr wr;
30 struct ibv_send_wr *bad_wr = NULL;
31
32 memset(&wr, 0, sizeof(wr));
33 wr.wr_id = (uintptr_t)conn;
34 wr.opcode = IBV_WR_SEND;
35 wr.sg_list = &sge;
36 wr.num_sge = 1;
37 wr.send_flags = IBV_SEND_SIGNALED;
38
39 /* 3. Now send ... */
40 ibv_post_send(conn->qp, &wr, &bad_wr);
41
42 ...<snip>...
43 }
부록 1: OFED 동사
