
NVMeDirect 논문 리뷰
이 눈문을 참조하면 SPDK/NVMe의 설계 아이디어를 잘 이해할 수 있습니다.
NVMeDirect: A User-space I/O Framework for Application-specific Optimization on NVMe SSDs
Abstract
SSD(Solid State Drive) 및 NVMe(Non-Volatile Memory Express) 인터페이스와 같은 새로운 기술로 인해 저장 장치의 성능이 크게 향상되었지만, 커널의 복잡한 I/O 스택은 NVMe의 전체 성능을 활용하는데 방해가 됩니다. 커널이 일반성과 공정성을 제공해야 하기 때문에 커널에서 응용 프로그램별 최적화도 어렵습니다.
본 논문에서는 사용자 애플리케이션이 하드웨어 수정 없이 상용 NVMe SSD에 직접 액세스할 수 있도록 하는 사용자 수준 I/O 아키텍처를 제안합니다. 또한 프레임워크는 사용자에게 유연성을 제공하며 사용자 애플리케이션은 I/O 완료 방법, 캐시 및 I/O 스케줄링을 포함하여 자체 I/O 전략을 선택할 수 있습니다. 평가 결과, 제안한 프레임워크는 마이크로 벤치마크에서 최대 30%의 성능 향상과 Redis에 적용했을 때 최대 15%의 성능 향상으로 커널 기반 I/O를 능가하는 것으로 나타났습니다.
1. Introduction
새로운 기술은 저장 장치의 성능을 눈부시게 발전시키고 있으며, NAND 플래시 기반의 SSD(Solid State Drive)는 하드 디스크 드라이브(HDD)를 대신하여 널리 채택되고 있습니다. 저장 장치 개발의 다음 단계는 3D XPoint와 같은 차세대 NVM이 될 것입니다. 스토리지 성능을 향상시키기 위해 고성능 PCIe 기반 스토리지 장치를 지원하도록 새로운 NVMe 인터페이스가 표준화되었습니다.
저장 장치의 속도가 빨라짐에 따라 느린 HDD에 최적화된 레거시 커널 I/O 스택의 오버헤드가 눈에 띄게 되는데, 이를 극복하기 위해 많은 연구자들이 폴링 메커니즘을 사용하여 커널 오버헤드를 줄이고 불필요한 컨텍스트 전환을 제거해 왔습니다.
그러나 커널 수준의 I/O 최적화는 사용자 응용 프로그램의 요구 사항을 충족시키기에는 몇 가지 제한 사항이 있습니다. 첫째, 커널은 모든 하드웨어 리소스를 관리하는 응용 프로그램에 대한 추상화 계층을 제공하므로 일반적이어야 합니다. 둘째, 커널은 응용 프로그램 간에 공정성을 제공해야 하므로 특정 응용 프로그램에 유리한 정책을 구현할 수 없습니다. 마지막으로 커널을 자주 업데이트하려면 이러한 종류의 애플리케이션 최적화를 지원하기 위해 지속적인 투자가 필요합니다.
이러한 의미에서 커널의 개입 없이 사용자 공간에서 I/O 스택의 최적화를 가능하게 하는 고성능 저장 장치를 위한 사용자 공간 I/O 프레임워크의 지원이 바람직할 것입니다. 특히 이러한 사용자 공간 I/O 프레임워크는 I/O 성능이 전체 성능에서 중요한 역할을 하는 분산 데이터 처리 플랫폼, NoSQL 시스템 및 데이터베이스 시스템과 같은 최신 데이터 집약적 애플리케이션에 큰 영향을 미칠 수 있습니다. 최근 Intel은 사용자 공간에서 NVMe SSD에 액세스하기 위한 SPDK라는 도구 및 라이브러리를 출시했습니다. 그러나 SPDK는 전체 NVMe 드라이버를 커널 공간에서 사용자 공간으로 옮기기 때문에 단일 사용자 및 단일 애플리케이션에만 동작합니다.
본 논문에서는 사용자 애플리케이션이 저장 장치에 직접 접근할 수 있도록 하여 성능을 향상시키는 새로운 사용자 레벨 I/O 프레임워크인 NVMeDirect를 제안한다. 우리의 접근 방식은 표준 NVMe 인터페이스를 활용하고 하드웨어 수정 없이 상용 NVMe SSD에서 동작합니다. 사용자 공간 I/O 프레임워크는 실제 I/O 중에 커널을 거치지 않기 때문에 많은 최적화 기회를 허용합니다. SPDK와 달리 NVMeDirect는 커널의 레거시 I/O 스택과 공존할 수 있으므로 기존(커널 기반) 애플리케이션은 동일한 NVMe SSD를 NVMeDirect 지원 애플리케이션과 함께 서로 다른 디스크 파티션에서 동시에 사용할 수 있습니다. SPDK에 비해 NVMeDirect의 또 다른 이점은 제안된 프레임워크가 큐 관리, I/O 완료 방법, 캐싱 및 각 사용자 애플리케이션이 I/O 특성 및 요구 사항에 따라 자체 I/O 정책을 선택할 수 있는 I/O 스케줄링에 유연성을 제공하는 점입니다. 예를 들어 최저 지연 애플리케이션의 경우, 전용 대기열을 할당하고 NVMe SSD에 직접 I/O 명령을 내린 후 폴링 메커니즘을 사용 가능 합니다. 우선 순위가 높은 I/O 요청에 대한 대기열을 분리하여 애플리케이션 내부에 차별화된 I/O 서비스를 구현할 수도 있습니다. 이는 전체 성능을 향상시키기 위해 로깅 I/O 성능을 높이는 것이 중요한 것으로 알려진 데이터베이스 서버에 유용할 수 있습니다.
2. Background
NVMe(NVM Express)는 PCIe 기반 SSD를 위한 확장 가능한 고성능 호스트 컨트롤러 인터페이스입니다. NVMe의 주목할만한 기능은 I/O 명령을 처리하기 위해 여러 대기열을 제공한다는 것입니다. 각 I/O 대기열은 최대 64K 명령을 관리할 수 있으며 단일 NVMe 장치는 최대 64K I/O 대기열을 지원합니다. I/O 명령을 내릴 때 호스트 시스템은 명령을 제출 대기열에 넣고 초인종 레지스터를 사용하여 NVMe 장치에 알립니다. NVMe 장치가 I/O 명령을 처리한 후 결과를 완료 대기열에 쓰고 호스트 시스템에 인터럽트를 발생시킵니다. NVMe는 MSI/MSI-X 및 인터럽트 집계에 의한 인터럽트 처리 성능을 향상시킵니다. 현재 리눅스 커널에서는 NVMe 드라이버는 잠금 및 캐시 충돌을 방지하기 위해 호스트 시스템의 코어당 제출 대기열 및 완료 대기열을 생성합니다.
3. NVMeDirect I/O Framework
3.1 Design
사용자 애플리케이션의 다양한 요구 사항을 충족하면서 NVMe SSD의 성능을 최대한 활용하기 위해 NVMeDirect라는 사용자 공간 I/O 프레임워크를 개발합니다. 그림 1은 NVMeDirect 프레임워크의 전체 아키텍처를 보여줍니다.
관리 도구는 루트 권한으로 커널 드라이버를 제어하여 I/O 대기열의 액세스 권한을 관리합니다. 응용 프로그램이 NVMeDirect에 단일 I/O 대기열을 요청하면 사용자 수준 라이브러리가 커널 드라이버를 호출합니다. 커널은 먼저 애플리케이션이 사용자 수준 I/O를 수행할 수 있는지 여부를 확인한 다음 필요한 제출 큐(SQ) 및 완료 큐(CQ)를 생성하고 해당 메모리 영역 및 관련 초인종 레지스터를 애플리케이션의 사용자 공간 메모리 영역에 매핑합니다. 이 초기화 후 애플리케이션은 하드웨어 수정이나 커널 I/O 스택의 도움 없이 NVMe SSD에 직접 I/O 명령을 내릴 수 있습니다. NVMeDirect는 NVMe 대기열에 I/O 요청을 보내는 I/O 핸들의 개념을 제공합니다. 쓰레드는 하나 이상의 I/O 핸들을 생성하여 큐에 액세스할 수 있으며 각 핸들은 전용 큐 또는 공유 큐에 바인딩될 수 있으며 워크로드의 특성에 따라 캐싱과 같은 다른 기능을 사용하도록 각 핸들을 구성할 수 있습니다. I/O 스케줄링 및 I/O 완료 NVMeDirect 프레임워크에서 지원하는 주요 API는 표 1에 요약되어 있습니다. NVMeDirect는 또한 읽기, 쓰기, flush 및 discard와 같은 NVMe 명령에 해당하는 다양한 래퍼 API를 제공합니다.
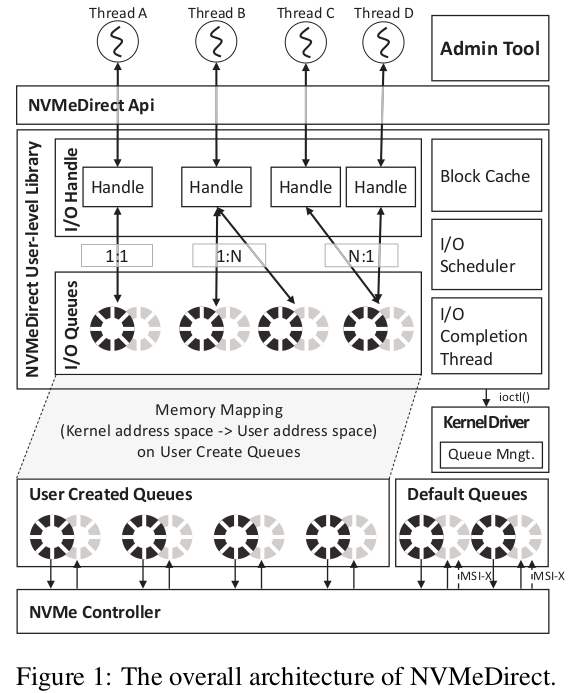
큐에서 핸들을 분리하면 여러 쓰레드 간에 유연한 그룹화된 I/O 정책이 가능하고 차별화된 I/O 서비스를 쉽게 구현할 수 있습니다. 일반적으로 단일 I/O 큐는 그림 1의 쓰레드 A와 같은 단일 핸들에 바인딩됩니다. 쓰레드가 일괄 쓰기로 인한 읽기 부족 문제를 피하기 위해 쓰기 요청에서 읽기 요청을 분리해야 하는 경우 그림 1의 스레드 B와 같이 여러 대기열을 단일 핸들에 바인딩할 수 있습니다. 그림 1의 쓰레드 C와 D와 같이 여러 쓰레드 간에 단일 대기열을 공유하는 것도 가능합니다.
NVMeDirect는 또한 다양한 I/O 정책을 지원하기 위해 블록 캐시, I/O 스케줄러 및 I/O 완료 쓰레드 구성 요소를 제공합니다. 애플리케이션은 필요에 따라 이러한 구성 요소를 혼합하고 조정할 수 있습니다. 커널 페이지 캐시와 유사하게 블록 캐시는 4KB 단위로 메모리 I/O를 처리합니다. NVMe 인터페이스는 물리적 메모리 주소를 사용하여 I/O 명령을 전송하므로 블록 캐시에 있는 메모리는 사전 변환된 물리적 주소를 사용하여 주소 변환 오버헤드를 방지합니다. I/O 스케줄러는 비동기 I/O 작업 또는 블록 캐시의 I/O 요청으로 I/O 명령을 실행합니다. 인터럽트 기반 I/O 완료는 컨텍스트 전환 및 추가 소프트웨어 오버헤드를 유발하므로 고성능 및 대기 시간이 짧은 I/O 장치에는 적합하지 않습니다. 그러나 응용 프로그램이 대역폭에 민감하고 대기 시간에 덜 관심이 있는 경우 폴링은 CPU 부하를 크게 증가시키기 때문에 효율적이지 않습니다. 따라서 NVMeDirect는 불필요한 CPU 사용을 방지하기 위해 전용 폴링 스레드 및 애플리케이션 풋프린트를 활용합니다. 이 전용 폴링 스레드에는 I/O 크기에 기반한 동적 폴링 주기 제어 메커니즘이 있습니다.

3.2 Implementation
NVMeDirect 프레임워크는 큐 관리, 관리 도구 및 사용자 수준 라이브러리의 세 가지 구성 요소로 구성되며, 대기열 관리 및 관리 도구는 대부분 NVMe 커널 드라이버에서 구현되며 사용자 수준 라이브러리는 공유 라이브러리로 개발되었습니다.
Linux 커널 4.3.3의 NVMe 드라이버에 대기열 관리 모듈을 구현했습니다. 초기화 단계에서 관리 도구는 ioctl()을 사용하여 대기열 관리 모듈에 액세스 권한 및 사용 가능한 대기열 수를 알립니다. 애플리케이션이 대기열 생성을 요청하면 대기열 관리 모듈은 권한을 확인한 다음 제출 대기열(SQ)과 완료 대기열(CQ)을 포함하는 대기열 쌍(QP)을 생성합니다. 대기열 관리 모듈은 dma_common_mmap()을 사용하여 생성된 대기열 커널 공간과 초인종 레지스터의 메모리 주소를 사용자 모드 주소 공간에 매핑하여 사용자 수준 함수 라이브러리가 생성된 대기열과 초인종 레지스터를 볼 수 있도록 합니다. 대기열 관리 모듈은 또한 proc 파일 시스템을 사용하여 메모리 주소를 내보냅니다. 그런 다음 사용자 수준 라이브러리는 큐 및 초인종 레지스터의 메모리 주소에 액세스하여 I/O 명령을 실행할 수 있습니다. 폴링 주기는 애플리케이션의 I/O 특성에 따라 동적으로 조정할 수 있으며 애플리케이션은 nvmed_set_param()을 사용하여 특정 큐의 폴링 주기를 명시적으로 설정할 수 있으며 I/O 완료 스레드는 폴링 주기를 조정하기 위해 usleep()을 사용합니다.
4. Evaluation
Fio(Flexible IO Tester) 벤치마크를 사용하여 비동기 I/O(Kernel I/O)를 지원하는 커널 기반 NVMeDirect와 SPDK의 성능을 비교합니다. Ubuntu 14.04를 실행하는 3.3GHz Intel Core i7 CPU 및 64GB 메모리가 장착된 Linux 시스템을 사용합니다. 모든 성능 평가는 상용 Intel 750 시리즈 400GB NVMe SSD에서 수행되었습니다.
4.1 Baseline Performance
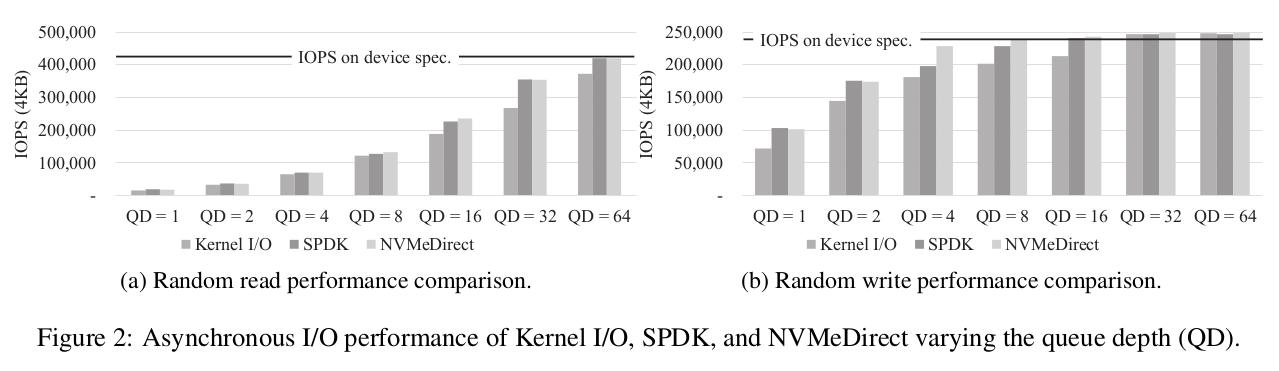
그림 2는 단일 스레드 및 다양한 대기열 깊이를 사용하는 NVMeDirect, SPDK 및 커널 I/O의 임의 읽기(그림 2a), 임의 쓰기(그림 2b) IOPS를 보여줍니다. 대기열 깊이가 충분히 크면 임의 읽기 및 쓰기 성능이 NVMeDirect, SPDK 또는 커널 I/O에 관계없이 장치의 성능 사양을 충족하거나 초과하지만 NVMeDirect는 IOPS가 포화될 때까지 커널 I/O에 비해 더 높은 IOPS를 달성합니다. 이는 NVMeDirect가 커널 I/O 스택의 오버헤드를 피하면서 사용자 애플리케이션이 NVMe SSD에 직접 액세스하도록 지원하기 때문입니다. 그림 2a에서 볼 수 있듯이 큐 깊이가 64일 때 NVMeDirect 프레임워크가 임의 읽기 중에 거의 최대 성능을 달성한다는 것을 알 수 있습니다. 동일한 구성에서 커널 I/O의 IOPS는 12% 적습니다. 그림 2b에서 NVMeDirect는 임의 쓰기 중에 장치의 최대 성능을 달성하는 반면 커널 I/O의 IOPS는 20% 적습니다. SPDK는 사용자 공간에서 NVMe SSD에도 직접 액세스하기 때문에 NVMeDirect와 동일한 추세를 보입니다.
4.2 Impact of the Polling Period
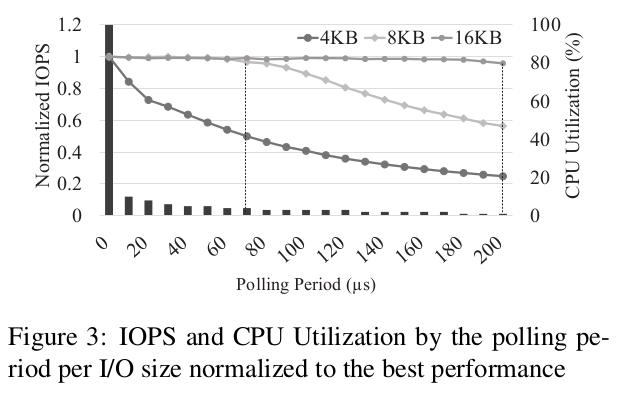
그림 3은 I/O 크기별로 폴링 주기를 다르게 했을 때 IOPS(선 그래프)와 CPU 사용률(막대로 표시)의 추이를 보여주고 있으며, 결과는 각 I/O 크기에 대해 지연 없이 폴링을 수행했을 때 달성되는 IOPS로 정규화됩니다. I/O 크기별로 특정 지점에서 상당한 성능 저하가 발생함을 알 수 있습니다. 예를 들어 I/O 크기가 4KB인 경우 I/O가 매우 빠르게 완료될 수 있으므로 폴링 주기를 최대한 줄이는 것이 좋습니다. I/O 크기가 8KB와 16KB일 때 폴링 주기가 70μs와 200μs 사이에서 변동하더라도 성능이 크게 떨어지지 않습니다. 폴링 쓰레드로 인한 CPU 사용률을 8KB I/O의 경우 4%, 16KB I/O의 경우 1%로 줄일 수 있습니다. 3.1절에서 언급한 바와 같이 폴링과 관련된 CPU 사용률을 줄이기 위해 이 결과를 기반으로 적응형 폴링 주기 제어 메커니즘을 사용합니다.
4.3 Latency Sensitive Application
짧은 대기 시간은 키-값 저장소와 같은 대기 시간에 민감한 애플리케이션에 특히 효과적입니다. Redis라는 대기 시간에 민감한 애플리케이션을 사용하여 NVMeDirect를 평가합니다. Redis는 주로 데이터베이스, 캐시 및 메시지 브로커에 사용되는 메모리 내 키-값 저장소입니다. Redis는 인메모리 데이터베이스이지만 Redis는 지속성을 제공하기 위해 모든 쓰기 명령에 대한 로그를 작성합니다. 이로 인해 쓰기 대기 시간이 Redis 성능에 매우 중요합니다. NVMeDirect에서 Redis를 실행하기 위해 Redis의 초기화 부분에 6줄의 코드를 추가하고 12줄의 코드를 수정했으며 POSIX I/O 인터페이스를 블록 캐시와 관련된 NVMeDirect 인터페이스로 교체했습니다. 우리는 10개의 클라이언트가 포함된 YSCB 기사에서 워크로드-A를 사용했는데 이는 업데이트가 많은 워크로드입니다.
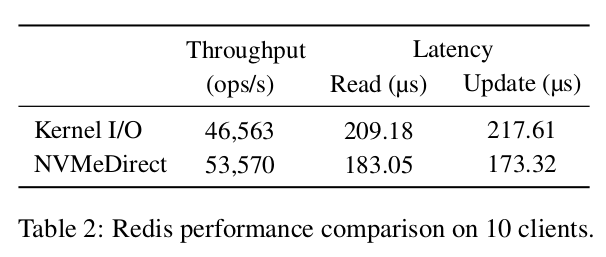
표 2는 커널 I/O 및 NVMeDirect에서 Redis의 처리량 및 대기 시간을 보여줍니다. NVMeDirect는 전체 처리량을 약 15% 향상시키고, 평균 읽기 대기 시간을 13%, 업데이트 작업 대기 시간을 20% 줄입니다. 이는 NVMeDirect가 커널 소프트웨어 오버헤드를 제거하여 대기 시간을 줄이기 때문입니다.
4.4 Differentiated I/O Service
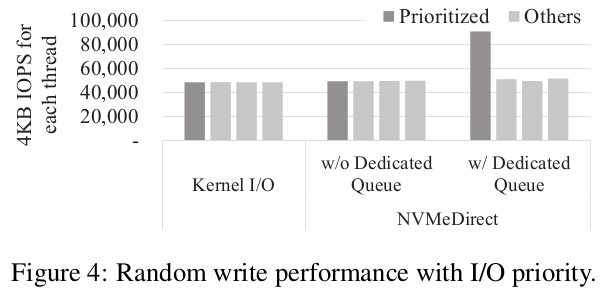
I/O 분류 및 우선 순위가 부여된 I/O의 부스팅은 데이터베이스 시스템에서 로그 쓰기와 같은 애플리케이션 성능을 향상시키는 데 중요합니다. NVMeDirect는 I/O 핸들과 여러 대기열을 사용하여 다양한 애플리케이션에 다양한 I/O 전략을 적용할 수 있기 때문에 차별화된 I/O 서비스를 쉽게 제공할 수 있습니다.
NVMeDirect에서 가능한 I/O 부스팅 방식을 시연하기 위한 실험을 수행했습니다. 특정 I/O를 부스트하기 위해 우선순위가 지정된 쓰레드를 전용 큐에 할당하고 다른 쓰레드는 단일 큐를 공유합니다. 비부스팅 모드의 경우, 각 쓰레드는 프레임워크에 고유한 대기열이 소유합니다. 그림 4는 fio 벤치마크를 실행하는 동안 커널 I/O와 NVMeDirect의 두 가지 I/O 부스팅 모드의 IOPS를 보여줍니다. 이 벤치마크는 우선 순위가 지정된 쓰레드 1개를 포함하여 4개의 쓰레드를 실행하고 각 스레드는 큐 깊이 4로 임의 쓰기를 수행합니다. 결과에서 볼 수 있듯이 NVMeDirect에 전용 큐가 있는 우선순위 쓰레드가 다른 쓰레드보다 월등히 뛰어난 성능을 보여 줍니다. Kernel I/O의 경우 우선 순위가 지정된 I/O를 지원하는 메커니즘이 없기 때문에 모든 쓰레드의 성능이 비슷합니다. 이 결과는 NVMeDirect가 추가적인 소프트웨어 오버헤드 없이 차별화된 I/O 서비스를 제공할 수 있음을 보여줍니다.
5. Related Work
하드웨어 대기 시간이 수 밀리초로 줄었기 때문에 업계에서는 스토리지 스택 최적화에 대한 연구를 수행해 왔습니다. Shin et al.[11]은 최적화된 기본 하드웨어 추상화 계층에 기반한 저지연 I/O 완료 기법을 제안했습니다. 특히 I/O 경로를 최적화하면 컨텍스트 전환으로 인한 스케줄링 지연이 최소화됩니다. Yu et al.[14]은 빠른 저장 장치의 성능을 최대한 활용하기 위해 몇 가지 최적화 방법을 제안했습니다. 최적화에는 I/O 완료를 위한 폴링, 컨텍스트 스위치 제거, I/O 병합 및 이중 버퍼링이 포함됩니다. Yang et al.[13]도 I/O 완료 폴링 방식이 기존의 인터럽트 기반 I/O보다 성능이 높다고 지적했습니다.
일부 최적화에도 불구하고 커널 오버헤드가 여전히 존재하므로 연구자들은 커널을 거치지 않고 직접 저장 장치에 액세스하려고 시도했습니다. Caulfield et al.[5]은 특별한 저장 장치(Moneta)를 기반으로 저장 액세스 대기 시간을 더욱 줄이기 위해 사용자 공간 소프트웨어 스택을 제안합니다. 유사하게 Volos et al.[12]은 스토리지 클래스 메모리를 사용자 애플리케이션에 노출하여 커널 상호 작용 없이 스토리지에 직접 액세스할 수 있는 유연한 파일 시스템 아키텍처를 제안합니다. 이러한 접근 방식은 제안된 NVMeDirect I/O 프레임워크와 유사합니다. 그러나 그들의 연구에는 특정 하드웨어가 필요한 반면 우리의 프레임워크는 상업적으로 사용 가능한 모든 NVMe SSD에서 실행할 수 있습니다. 또한 모든 애플리케이션에 필요하지 않은 공통 파일 시스템 계층을 제공하는 복잡한 모듈을 가지고 있습니다.
NVMeDirect는 Intel에서 발표한 SPDK와 독립적인 연구 결과입니다. NVMeDirect는 개념적으로는 SPDK와 유사하지만 NVMeDirect는 다음과 같은 차이점이 있습니다. 첫째, NVMeDirect는 컨트롤 플레인 작업에 커널 NVMe 드라이버를 활용하므로 기존 애플리케이션과 NVMeDirect 지원 애플리케이션이 동일한 NVMe SSD를 공유할 수 있습니다. 그러나 SPDK에서 NVMe SSD는 사용자 수준 드라이버 코드를 소유하는 특정 프로세스 전용입니다. 둘째, NVMeDirect는 사용자가 NVMe SSD에 직접 액세스할 수 있도록 하는 메커니즘이 아닙니다. 대신에 특성 및 요구 사항에 따라 다양한 데이터 집약적 애플리케이션을 최적화하기 위해 대규모 I/O 정책 세트를 제공하는 것을 목표로 합니다.
6. Conclusion
NVMe SSD에서 애플리케이션별 최적화를 가능하게 하는 사용자 공간 I/O 프레임워크인 NVMeDirect를 제안합니다. NVMeDirect를 사용하여 사용자 공간 애플리케이션은 커널 I/O 스택의 오버헤드 없이 NVMe SSD에 직접 액세스할 수 있습니다. 프레임워크는 애플리케이션의 요구에 따라 선택적으로 사용할 수 있는 여러 I/O 정책을 제공하며, 평가 결과 NVMeDirect는 여러 사용자 수준 I/O 최적화 기법을 사용하여 애플리케이션 성능을 향상시키는 효과적인 접근 방식임을 보여줍니다
NVMeDirect는 I/O 중에 커널과 상호 작용하지 않기 때문에 일반적으로 파일 시스템 계층에서 제공하는 충분한 액세스 보호를 제공하지 않습니다. 그럼에도 불구하고 우리는 여전히 NVMeDirect가 신뢰할 수 있는 환경에 배포되는 많은 데이터 집약적 애플리케이션에 유용하다고 믿습니다. 향후 불법적인 메모리/스토리지 액세스로부터 시스템을 보호하는 방법을 조사할 계획입니다. 또한 보다 다양한 애플리케이션 시나리오를 지원하기 위해 사용자 수준의 파일 시스템을 제공할 계획입니다. NVMeDirect의 소스 코드는 https://github.com/nvmedirect에서 오픈 소스로 제공됩니다.